pgvector의 HNSW 인덱스로 벡터 검색을 구현할 때 반드시 알아야 할 것들을 기록합니다. iterative_scan의 동작 원리, 필터링 전략, 성능 최적화까지 정리하였습니다. 모든 글과 이미지는 claude code로 제작되었습니다.
Introduction
- pgvector는 PostgreSQL에서 벡터 검색을 구현할 수 있게 해주는 확장(extension)1
- 별도의 벡터 DB를 도입하지 않고도, 기존 PostgreSQL 인프라에서 ANN(Approximate Nearest Neighbor) 검색이 가능
- pgvector는 HNSW와 IVFFlat 두 종류의 ANN 인덱스를 제공하며, 이 글에서는 주로 HNSW 인덱스를 다룸
HNSW(Hierarchical Navigable Small World)는 그래프 기반의 ANN 알고리즘으로, 빠른 검색 속도와 높은 recall을 동시에 제공함2. 하지만 WHERE 필터와 함께 사용할 때 예상치 못한 함정이 존재하며, 이를 이해하지 못하면 심각한 결과 누락이 발생할 수 있음
이 글에서는 다음 내용을 다룸
- HNSW + WHERE 필터 사용 시 발생하는 결과 누락 문제와 해결 방법
- Prefilter vs Postfilter 전략 비교
- HNSW 파라미터 튜닝 가이드
- 인덱스 크기 관리와 halfvec 최적화
iterative_scan Problem
Incomplete Results Problem
pgvector HNSW 인덱스를 사용할 때, WHERE 필터가 HNSW partial index 조건에 포함되지 않으면 요청한 LIMIT보다 훨씬 적은 결과가 반환될 수 있음
-- HNSW partial index: WHERE embedding_type = 'image' (300만 행)
-- 쿼리에는 model_id 필터 추가 (인덱스에 없는 조건)
SELECT id, embedding <=> :query AS distance
FROM embeddings
WHERE embedding_type = 'image' -- HNSW partial index 조건
AND model_id = :target_model -- 인덱스에 없는 필터!
ORDER BY embedding <=> :query
LIMIT 1000;이 쿼리가 LIMIT 1000을 요청했는데 그보다 훨 씬 적은 수가 반환된다면, hnsw.iterative_scan이 꺼져 있기 때문
Why This Happens
HNSW 인덱스는 그래프 기반 탐색을 수행함. iterative_scan = off(기본값)일 때의 동작:
- HNSW 그래프에서
ef_search(기본 40)개의 가장 가까운 후보를 찾음 - 찾은 후보들을 PostgreSQL에 반환
- PostgreSQL이 WHERE 조건(
model_id = ?)을 적용해 필터링 - 필터를 통과한 결과만 남음 — 전체의 50%가 다른 모델이면 ~20개만 남음
- LIMIT 1000이지만 20개로 끝. HNSW는 이미 탐색을 마침
핵심은 HNSW가 "40개 찾았으니 끝"이라고 판단하고, PostgreSQL이 "아직 1000개 안 채웠는데"라고 해도 더 탐색하지 않는다는 것
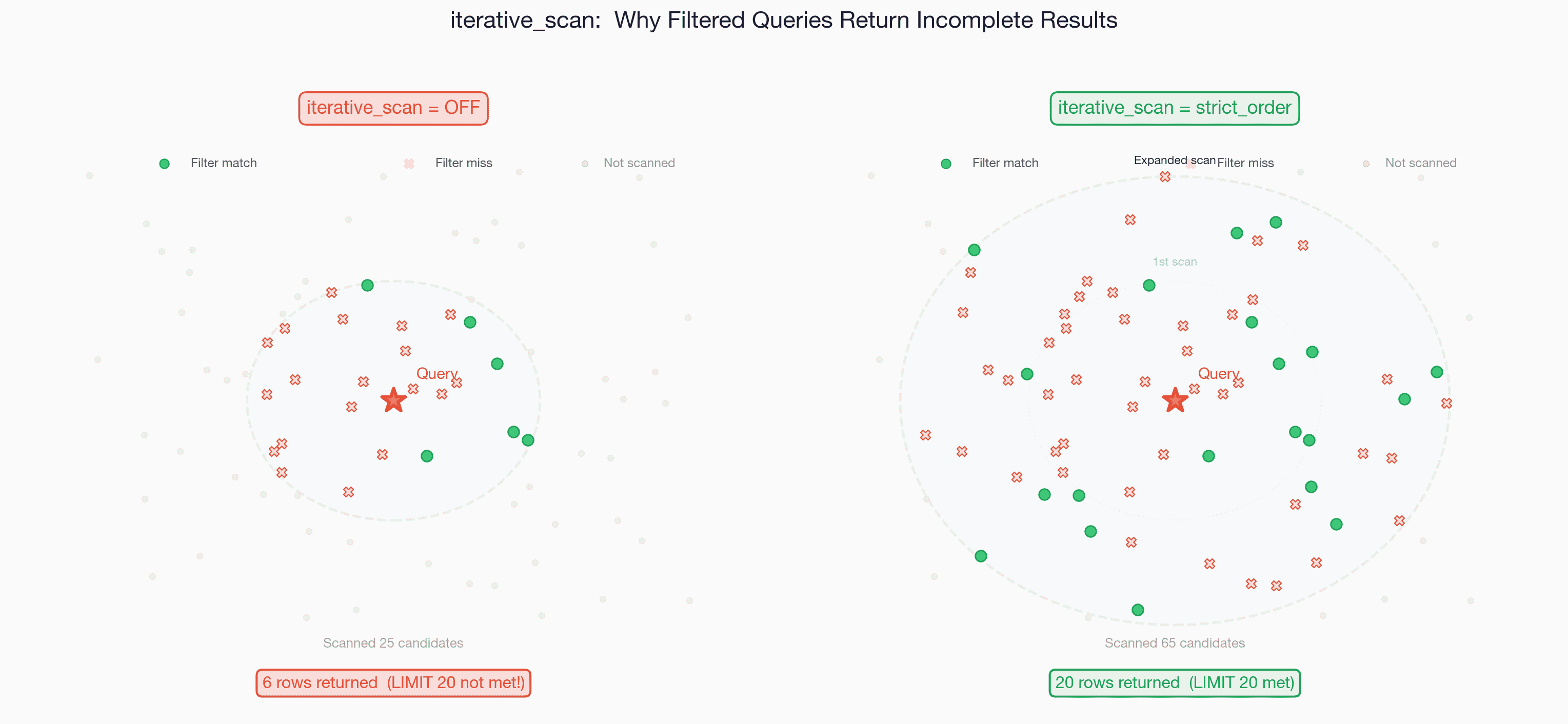
위 그림은 이 문제를 단순화하여 보여줌 (LIMIT 20 기준). 왼쪽(OFF)은 HNSW가 소수의 후보만 스캔한 뒤 종료하여, 필터를 통과한 결과(초록 점)가 LIMIT에 크게 미달함. 오른쪽(strict_order)은 LIMIT이 채워질 때까지 스캔 범위를 반복적으로 확장하여 충분한 결과를 확보함. 실제 LIMIT 1000 같은 큰 값에서도 동일한 원리가 적용됨
iterative_scan Modes
hnsw.iterative_scan은 pgvector 0.8.0에서 도입된 세션 레벨 파라미터3. WHERE 필터 조건을 만족하는 결과가 LIMIT개만큼 채워질 때까지 HNSW 탐색을 반복하는 기능
| 모드 | 동작 | 거리 순서 보장 | 용도 |
|---|---|---|---|
off (기본값) |
1회 탐색 후 종료 | O | 필터 없는 단순 검색 |
strict_order |
LIMIT 채울 때까지 반복 | O | 필터 있으면 반드시 사용 |
relaxed_order |
반복 탐색, 근사 순서 | X (근사) | 속도 우선 |
LIMIT에 도달하거나 max_scan_tuples에 도달할 때까지 탐색을 계속함
Usage
-- 트랜잭션 내에서만 유효 (다른 세션에 영향 없음)
SET LOCAL hnsw.iterative_scan = strict_order;
SET LOCAL hnsw.ef_search = 100;
-- 이후 벡터 검색 쿼리 실행
SELECT id, embedding <=> :query AS distance
FROM embeddings
WHERE embedding_type = 'image' AND model_id = :target_model
ORDER BY embedding <=> :query
LIMIT 1000;SQLAlchemy에서는:
await db.execute(text("SET LOCAL hnsw.iterative_scan = strict_order"))
await db.execute(text("SET LOCAL hnsw.ef_search = 100"))
# 이후 ORM 쿼리 실행Prefilter vs Postfilter
벡터 검색에서 구조화된 필터(카테고리, 테넌트 ID, 날짜 범위 등)를 적용하는 두 가지 전략
Postfilter Problem
- 특정 카테고리가 전체의 10%라면, top-1000 중 ~100개만 남음
- LIMIT을 50,000으로 올려도 근본적으로 해결 안 됨 (HNSW에서 대량 fetch는 매우 느림)
Prefilter 1: JOIN + ORDER BY
SELECT e.id, e.embedding <=> :query AS distance
FROM embeddings e
JOIN items i ON e.item_id = i.id
WHERE e.embedding_type = 'image'
AND i.category = 'character'
AND i.tenant_id = 'tenant_a'
ORDER BY e.embedding <=> :query
LIMIT 1000;iterative_scan이 켜져 있으면 JOIN + WHERE 조건을 만족하는 행이 LIMIT개 될 때까지 계속 스캔- 장점: 구현 간단, 추가 인덱스 불필요
- 단점: PostgreSQL 플래너가 HNSW 인덱스를 안 탈 수 있음 (JOIN이 복잡하거나 필터 선택도가 낮을 때)
Prefilter 2: Denormalization + Partial Index
-- 임베딩 테이블에 자주 쓰는 필터 컬럼을 복제
ALTER TABLE embeddings ADD COLUMN tenant_id VARCHAR(50);
-- 테넌트별 HNSW partial index
CREATE INDEX idx_hnsw_tenant_a ON embeddings
USING hnsw (embedding vector_cosine_ops)
WHERE embedding_type = 'image' AND tenant_id = 'tenant_a';- 장점: HNSW 인덱스가 확실히 사용됨. 인덱스 크기도 줄어들어 성능 향상
- 단점: 데이터 동기화 오버헤드. 테넌트가 많으면 인덱스도 많아짐
Prefilter 3: Table Partitioning
CREATE TABLE embeddings (...) PARTITION BY LIST (tenant_id);
CREATE TABLE embeddings_tenant_a PARTITION OF embeddings
FOR VALUES IN ('tenant_a');
-- 각 파티션에 자동으로 HNSW 인덱스 생성- 장점: PostgreSQL이 파티션 프루닝으로 자동 최적화. 인덱스 관리가 체계적
- 단점: 스키마 변경이 큼. 파티션 키 선택이 중요
Prefilter Planner Behavior
주의할 점은 필터 선택도에 따라 PostgreSQL 플래너가 HNSW 인덱스를 사용하지 않을 수 있다는 것
- 필터 선택도가 높으면(해당 조건에 맞는 행이 많으면) 플래너가 HNSW 인덱스를 정상적으로 사용
- 필터 선택도가 낮으면(해당 조건에 맞는 행이 매우 적으면) 플래너가 HNSW를 아예 포기하고 Bitmap Heap Scan 등 전체 스캔 + 정렬로 전환
- 결과는 정확하지만 매우 느림
- 이런 경우 방법 2(비정규화)나 방법 3(파티셔닝)이 필요
HNSW Parameters
Index Build Parameters
CREATE INDEX 시 설정하며, 변경 시 리빌드 필요
| 파라미터 | 기본값 | 설명 | 영향 |
|---|---|---|---|
m |
16 | 각 노드의 최대 연결(엣지) 수 | 높을수록 recall↑, 인덱스 크기↑, 빌드 느림 |
ef_construction |
64 | 빌드 시 탐색 후보 수 | 높을수록 그래프 품질↑, 빌드 느림, 크기 불변 |
m: 인덱스 크기를 직접 결정하는 유일한 파라미터. 각 벡터가 최대 m개의 이웃과 연결됨. 권장 범위 5~48ef_construction: 빌드 시에만 영향. 새 벡터를 삽입할 때 ef_construction개의 후보를 탐색하고 그 중 m개와 연결. 64 vs 200의 recall 차이는 보통 1~3%
Query Parameters
SET으로 세션 레벨 설정, 즉시 적용
| 파라미터 | 기본값 | 설명 | 영향 |
|---|---|---|---|
hnsw.ef_search |
40 | 쿼리 시 탐색 후보 수 | 높을수록 recall↑, 속도↓ |
hnsw.iterative_scan |
off | 반복 탐색 모드 | 필터 있으면 반드시 켜야 함 |
hnsw.max_scan_tuples |
20000 | 반복 탐색 시 최대 방문 튜플 수 | 초과 시 탐색 중단 |
hnsw.scan_mem_multiplier |
1 | 반복 탐색 메모리 = work_mem × 이 값 | 메모리 부족 시 올리기 |
ef_construction vs ef_search
이름이 비슷하여 자주 혼동되는 두 파라미터
| ef_construction | ef_search | |
|---|---|---|
| 언제 | 인덱스 빌드 시 (1회) | 검색 쿼리 시 (매번) |
| 역할 | 그래프 연결 품질 결정 | 검색 탐색 범위 결정 |
| 올리면 | 빌드 느려짐, recall 소폭 향상 | 검색 느려짐, recall 향상 |
| 인덱스 크기 | 영향 없음 (m이 결정) |
영향 없음 |
| 변경 비용 | 인덱스 리빌드 필요 (수 시간) | SET 한 줄로 즉시 적용 |
검색 품질이 부족하면 ef_search부터 올려보는 것을 권장. 리빌드 없이 즉시 테스트 가능
Index Size and Memory
Index Size Estimation
HNSW 인덱스 크기 ≈ 벡터 수 × 차원 × 4 bytes × (1 + m × 오버헤드)| 벡터 수 | 차원 | m | 예상 인덱스 크기 |
|---|---|---|---|
| 100만 | 1024 | 16 | ~5 GB |
| 300만 | 1024 | 16 | ~15 GB |
| 1000만 | 1024 | 16 | ~50 GB |
| 300만 | 512 | 16 | ~7.5 GB |
When Index Exceeds shared_buffers
대규모 벡터 테이블에서 자주 발생하는 상황. 예를 들어 300만 × 1024차원이면 인덱스가 15GB인데, shared_buffers가 34GB인 구성은 흔함
증상:
- 첫 쿼리가 10초 이상 걸림 (콜드 캐시, 디스크 I/O)
- 반복 쿼리는 빠름 (OS 페이지 캐시 히트)
- 서버 재시작 후 다시 느림
대응 전략:
- pg_prewarm: 인덱스를 shared_buffers에 미리 로드. 단, 인덱스가 shared_buffers보다 크면 전체 로드 불가
SELECT pg_prewarm('idx_hnsw_image'); -- 가능한 만큼만 올림 - OS 페이지 캐시: shared_buffers 밖에도 OS가 자주 접근하는 페이지를 캐시. 트래픽이 꾸준하면 자연 워밍
- 인덱스 크기 축소: 가장 근본적인 해법. halfvec, 차원 축소, 불필요 데이터 삭제
- shared_buffers 증가: 인스턴스 메모리의 25~40% 권장. 인덱스 전체를 올릴 수 있으면 콜드 스타트 해결
halfvec Optimization
pgvector 0.7.0+에서 지원하는 반정밀도(float16) 벡터 타입4
| vector (float32) | halfvec (float16) | |
|---|---|---|
| 벡터당 크기 | 4 bytes × dim | 2 bytes × dim |
| 1024차원 기준 | 4 KB | 2 KB |
| 인덱스 크기 | 기준 | ~50% 감소 |
| recall 손실 | - | 거의 없음 (~0.1%) |
| 빌드 속도 | 기준 | ~2배 빠름 |
대부분의 임베딩 모델은 float16 정밀도에서도 검색 품질 손실이 무시할 수준
Method 1: Column Type Change
ALTER TABLE embeddings
ALTER COLUMN embedding TYPE halfvec(1024)
USING embedding::halfvec(1024);
CREATE INDEX CONCURRENTLY idx_hnsw_halfvec
ON embeddings USING hnsw (embedding halfvec_cosine_ops)
WITH (m = 16, ef_construction = 64)
WHERE embedding_type = 'image';Method 2: Index-only halfvec
-- 표현식 인덱스로 인덱스만 halfvec 사용
CREATE INDEX idx_hnsw_halfvec
ON embeddings
USING hnsw ((embedding::halfvec(1024)) halfvec_cosine_ops)
WHERE embedding_type = 'image';- 원본 데이터 정밀도를 유지하면서 인덱스 크기만 줄일 수 있음
- 리랭킹이 필요하면 원본 float32로 정확한 거리를 재계산 가능
Considerations
- 쿼리에서도
::halfvec(1024)캐스팅이 필요 - 임베딩 모델이 float16에서도 품질을 유지하는지 사전 테스트 권장
- 대부분의 모델에서 괜찮지만, 모델마다 다를 수 있음
Partial Index and Partitioning
HNSW 인덱스에서 필터링 성능을 개선하는 두 가지 구조적 접근
Partial Index
특정 WHERE 조건에 해당하는 행만 포함하는 인덱스
-- embedding_type별 분리 (기본)
CREATE INDEX idx_hnsw_image ON embeddings
USING hnsw (embedding vector_cosine_ops)
WHERE embedding_type = 'image';
-- 더 좁은 조건으로 분리 (성능 최적화)
CREATE INDEX idx_hnsw_image_model_a ON embeddings
USING hnsw (embedding vector_cosine_ops)
WHERE embedding_type = 'image' AND model_id = 'model_a';- 장점: 인덱스 크기 감소, 필터링 불필요, 탐색 속도 향상
- 단점: 조건이 동적이면 인덱스를 매번 생성해야 함. 조합이 많으면 인덱스 폭발
Table Partitioning
필터 컬럼 기준으로 테이블을 물리적으로 분리
CREATE TABLE embeddings (...) PARTITION BY LIST (model_id);
-- 각 파티션에 자동으로 HNSW 인덱스 생성 가능
CREATE TABLE embeddings_model_a PARTITION OF embeddings
FOR VALUES IN ('model_a');- 장점: PostgreSQL 파티션 프루닝으로 자동 최적화, 관리 체계적
- 단점: 스키마 변경이 큼, 파티션 키 선택이 중요 (나중에 바꾸기 어려움)
How to Choose
| 상황 | 추천 |
|---|---|
| 필터 값이 2~3개, 고정적 | Partial Index |
| 필터 값이 동적 또는 많음 | 테이블 파티셔닝 |
| 빠르게 적용해야 함 | iterative_scan + ef_search 튜닝 |
| 멀티테넌트 | 테이블 파티셔닝 |
HNSW vs IVFFlat
pgvector가 제공하는 두 가지 ANN(Approximate Nearest Neighbor) 인덱스
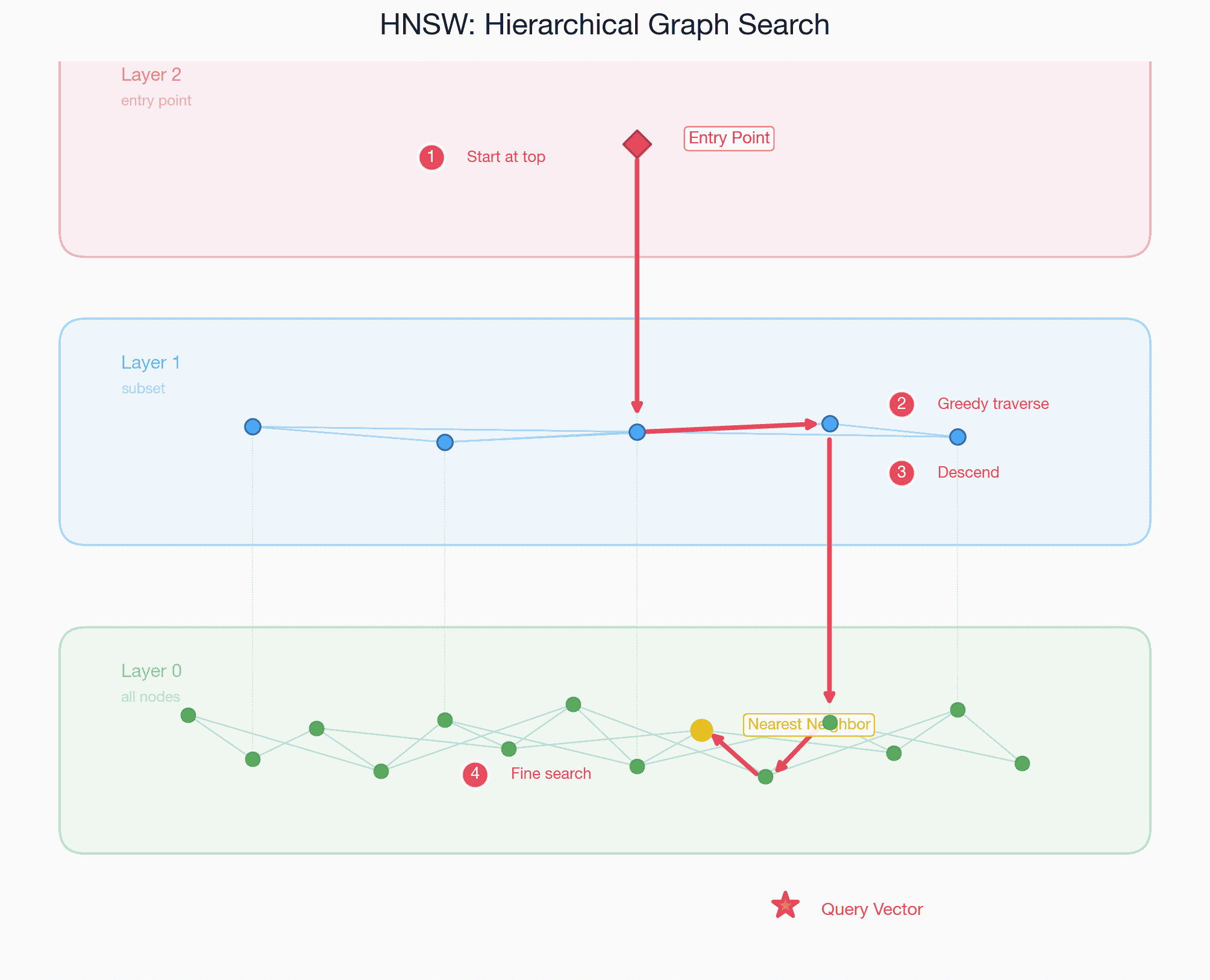
HNSW는 다층 그래프 구조에서 상위 레이어부터 greedy하게 탐색하며 하위 레이어로 내려가는 방식. 로그 스케일의 검색 속도를 제공함
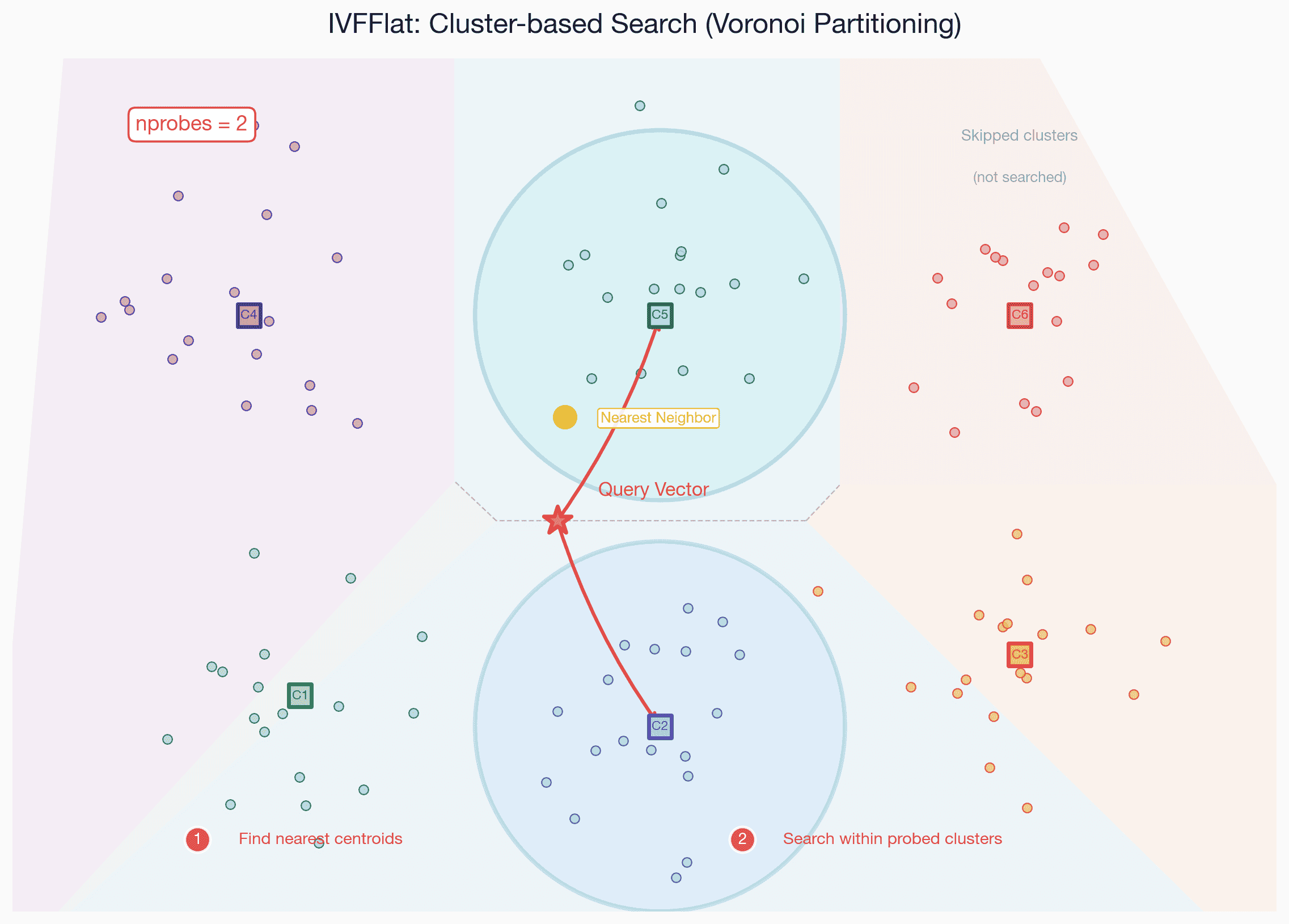
IVFFlat은 K-means로 벡터를 클러스터링한 뒤, 쿼리와 가장 가까운 centroid의 클러스터만 탐색하는 방식. nprobes 파라미터로 탐색할 클러스터 수를 조절
| HNSW | IVFFlat | |
|---|---|---|
| 알고리즘 | 계층적 그래프 탐색 | 클러스터링 + 리스트 스캔 |
| 검색 속도 | 빠름 (로그 스케일) | 보통 (리스트 수에 비례) |
| recall | 높음 (기본 설정에서도 양호) | 튜닝 필요 (probes 조정) |
| 인덱스 빌드 | 느림 (수 시간) | 빠름 (수 분) |
| 인덱스 크기 | 큼 (2~5배) | 작음 |
| 데이터 삽입 | 실시간 반영 (그래프 자동 적응) | 클러스터 불균형 → 주기적 리빌드 필요 |
| 필터링 | iterative scan | probes 조정 |
When to Choose HNSW
- 데이터가 지속적으로 추가/변경됨
- 검색 품질(recall)이 중요
- 인덱스 빌드 시간과 크기를 감당할 수 있음
When to Consider IVFFlat
- 데이터가 대부분 정적 (변경 거의 없음)
- 벡터가 수천만 이상으로 HNSW 메모리가 감당 안 될 때
- 인덱스 빌드를 빠르게 해야 할 때
Build Optimization
대규모 HNSW 인덱스 빌드(수백만 행)는 수 시간 소요될 수 있음. 최적화 방법:
Increase maintenance_work_mem
SET maintenance_work_mem = '8GB'; -- 빌드 시 임시로 올리기
CREATE INDEX CONCURRENTLY ...;
RESET maintenance_work_mem;그래프가 maintenance_work_mem에 들어가면 빌드가 훨씬 빠름
Parallel Build
SET max_parallel_maintenance_workers = 7; -- 기본 2pgvector 0.6+에서 HNSW 병렬 빌드를 지원함. Workers를 늘리면 빌드 시간 최대 30배 단축 가능5
CONCURRENTLY Option
CREATE INDEX CONCURRENTLY idx_name ON ...;- 테이블 락 없이 인덱스를 빌드함. 프로덕션에서 필수
- 단, 빌드 시간이 더 오래 걸리고 실패 시 INVALID 인덱스가 남을 수 있음
Cloud Environment Tips
- AWS Aurora: 빌드 시에만 인스턴스를 스케일업하고 완료 후 축소. Serverless v2는 이 패턴에 적합
- maintenance_work_mem은 인스턴스 메모리의 50~70%까지 올려도 빌드 전용이라 안전
Optimization Roadmap
pgvector HNSW 벡터 검색 최적화의 권장 순서
- 즉시 적용 (코드 변경만):
iterative_scan = strict_order,ef_search상향 (40 → 100) - 데이터 정리: 미사용 모델 데이터 삭제, 불필요 임베딩 타입 정리
- 인덱스 최적화: halfvec 전환(크기 50%↓), per-condition partial index, shared_buffers 증가
- 구조적 변경: 테이블 파티셔닝, 차원 축소(1024 → 512), 전용 벡터 DB 검토