이번 포스팅 에서는 Parisi, German I., et al.의 Continual lifelong learning suvery1와, Masana, Marc, et al.의 Class incremental learning survey2, 그리고 Liu, Bing의 Learning on the job3 논문을 참고하여 Continual lifelong learning에 대해서 정리합니다. 여러 연구 갈래 중에서, 특히 class-incremental learning2을 중심으로 정리하였습니다.
Introduction
사람은 일생 동안 여러 환경 속에서 다양한 지식과 능력을 습득하고, 해당 지식과 능력을 매번 더 나은 방향으로 수정하고, 이전에 겪지 못한 상황에 마주하더라도 지금까지 배운 것을 바탕으로 빠르게 적응하곤 합니다. 이러한 능력이나 학습 과정을 lifelong learning이라고 합니다.
하지만 사람에 비해 현재의 인공지능은 lifelong learning 능력이 부족합니다. Continual lifelong learning 연구들은 이미 학습한 task에 대해서는 다시 접근할 수 없다는 것을 기본 전제로 하는데, 만약 이런 문제 상황에서 새로운 task에 대해 모델을 아주 단순히 fine-tuning 한다면, 인공지능 모델이 이전에 배운 지식에 대해 심각하게 잊어버리곤 합니다. 이러한 현상을 catastrophic forgetting이라고 말하며, continual lifelong learning 연구에서는 이러한 catastrophic forgetting의 방지 즉, '현재 task를 학습하면서 이전에 배운 task를 잊지 않는 것'을 핵심 주제로 다룹니다.
인공지능에게 continual lifelong learning 능력을 부여하는 것은 사람과 비슷한 인공지능을 만든다는 점 이외에도 몇 가지 중요성을 가집니다. 가장 간단한 예시로 autonomous agent를 생각해볼 수 있습니다. Autonomous agent는 외부 환경과 상호작용을 주고 받으면서 새로운 지식을 계속해서 학습해야 합니다. 한 번의 학습이 완료되더라도, 아예 처음 마주하는 새로운 환경에 대해서 기존 지식을 활용하여 새로운 지식을 습득하고, 새로운 지식을 기반으로 기존 지식을 보완하는 것이 자연스럽습니다.
Agent가 아닌 일반적인 머신러닝 모델에 대해서도 continual lifelong learning은 아래와 같은 장점을 갖습니다.
- 이전에 학습한 지식에 대한 저장공간 부족 문제 해결 가능 (Memory restrictions)
- 모델 성능 유지를 위해서 로컬 데이터가 중앙 서버에 영원히 저장되지 않는 것이 가능(Data security / Privacy restrictions)
- 전체 데이터에 대한 재학습 없이 새로운 데이터만 학습이 가능하여 계산 cost 절약 (Sustainable ICT)
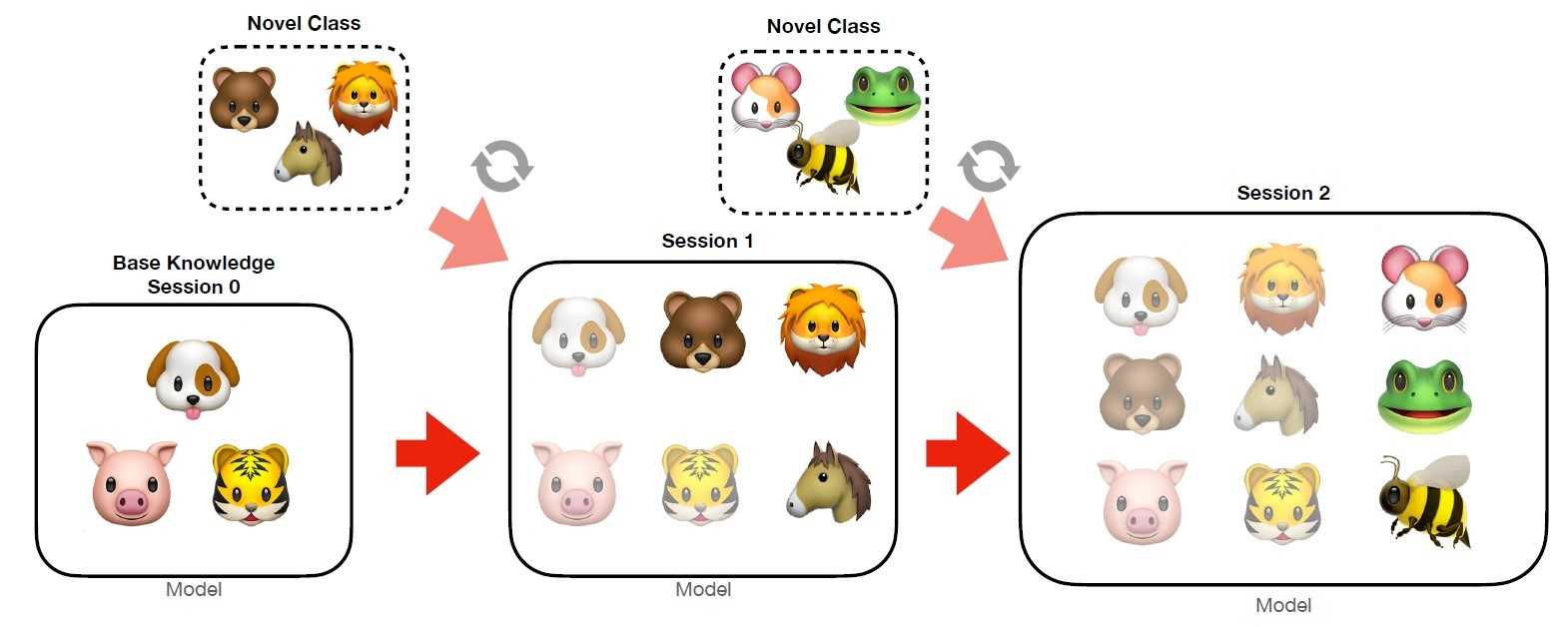
Class-incremental learning (made by
Definitions
실제 연구들을 살펴보기 앞서, continual learning, lifelong learning, incremental learning이 각각 어떤 것을 의미하는지 논문들의 표현을 빌려서 정리해보도록 하겠습니다. 결론부터 말씀드리자면 '세 용어 모두 자주 혼용되며, 연구자들도 명확히 구분지어서 사용하지는 않는다'입니다.
이 세 가지 learning 패러다임들이 하고자 하는 것은 new task를 past model에 대한 forgetting 없이 잘 배우자는 것으로 모두 동일한 목적성을 가지고 있습니다. 다만 Liu3 논문의 설명에 따르면 각각 약간의 차이가 존재하긴 합니다.
먼저, lifelong learning은 지금까지 배운 지식()을 기반으로 새로운 을 잘 학습하는 것에 집중합니다. 처음 학습을 시작한 이후로 learner는 개의 sequence of tasks 를 학습하는데, 이후에 번 째 task인 을 마주했을 때 knowledge base를 을 학습하기 위해 활용할 수 있어야 합니다. Knowledge base는 previous tasks에 대한 지식을 유지 및 축적하고 있는 공간을 의미하며, 을 학습한 이후에 새롭게 얻은 지식을 knowledge base에 업데이트합니다.
이와 달리 continual learning은 catastrophic forgetting을 막는 것에 집중합니다. 일반적으로 딥러닝 커뮤니티에서는 continual learning이라는 용어가 더 흔하게 사용됩니다. 이전에 배운 지식을 통해 새로운 지식으로 확장하는 연구보다, 새로운 지식을 배우는 과정에서 기존에 배운 지식을 잊지 않도록 하는 연구들이 더 흔해서 continual learning이라는 용어가 자주 등장하지 않나 싶습니다.
Incremental learning이라는 용어도 종종 등장하는데요, Masana, Marc, et al.2 의 설명에 따르면 incremental learning은 continual learning의 일종이며, continual learning은 supervised data 뿐만 아니라 RL에서도 사용되는 용어이지만, incremental learning은 주로 supervised data에 대해서 다룬다고 말하고 있습니다. 하지만 이 역시도 자주 혼용되며 명확히 구분짓기는 힘들다고 합니다. 개인적으로 여러 논문들을 살펴보며, zero base로 시작하는 경우엔 continual learning과 incremental learning이라는 용어를 혼용하고, 어떤 특정 pretrain 지점에서 시작하여 지식을 확장해나가면 incremental learning이라는 용어를 많이 사용한다고 느꼈습니다.
추가적으로 knowledge transfer라는 용어도 알아두시면 좋습니다. Knowledge transfer는 forward knowledge transfer와 backward knowledge transfer로 나뉘며, forward knowledge transfer는 이전 task를 학습함으로써 이후 task의 학습을 돕는 상황을 말하고, backward knowledge transfer는 이후 task를 학습함으로써 이전 task의 성능이 증가하는 상황을 말합니다.
Setup
저는 continual learning, lifelong learning, incremental learning 내 다양한 연구 갈래 중, class의 개수가 순차적으로 증가하는 class-incrementral learning을 중심으로 이번 포스팅을 작성하였습니다. Class-incremental learning 연구의 기본적인 셋업은 다음과 같습니다.
-
Task: classes들의 집합. 다른 tasks의 classes와는 disjoint 해야 함
-
Session: Learner는 오직 해당 session의 single task에 해당하는 데이터만 접근이 가능함. 다만 exemplar-based method에 대해서는 일정 memory 공간 만큼 다른 session의 데이터 사용을 허가. 해당 학습 session에서는 현재 task의 학습 데이터를 여러 차례 처리(학습/iteration)하는 것이 허용됨. 이는 일부 online learning 세팅에서 데이터 샘플을 오직 한 번 밖에 보지 못한다는 설정과는 차이를 가짐
-
Cross-entropy 계산: Exemplar-based 방식에 대해서는 (1)이 자연스러우나, exemplar-free 방식에서는 (2)가 forgetting 방지에 도움
- 현재 session의 데이터 샘플에 대한 corss-entropy를, 모든 class candidate를 대상으로 계산한 뒤 역전파
- 현재 session의 데이터 샘플에 대한 corss-entropy를, 현재 session의 novel class candidate를 대상으로만 계산 후 역전파
-
Datasets: CIFAR-100, Oxford Flowers, MIT Indoor Scenes, CUB-200-2011 Birds, Stanford Cars, FGVC Aircraft, Stanford Actions, VGGFace2, ImageNet dataset (and reduced ImageNet-subset) 등 사용
-
Metrics: 일반적으로 모든 class의 비율을 동일하게 고려하는 accuracy인 average accuracy 사용
-
Experimental scenarios (CIFAR-100를 예시로 들겠습니다)
- Zero-base 시작: class 100개를 가진 CIFAR-100에 대해서, 각 10 classes로 이루어진 10개의 tasks 구성
- Pretrain 후 시작: class 100개를 가진 CIFAR-100에 대해서, 첫 번째 task는 50 classes로 구성하고, 나머지 50개 class를 각 5개씩 10개의 tasks로 구성
Approaches
기존의 SOTA 모델들은 stationary batch를 통해 representation을 학습합니다. 하지만 continual learning, lifelong learning, incremental learning 문제 상황과 같이 non-stationary 데이터를 통한 학습은 catastrophic forgetting를 유발합니다. 이런 catastrophic forgetting의 원인에 대해 Masana, Marc, et al.2 은 다음과 같이 설명하고 있습니다.
- Old task와 관련된 네트워크 weight이 new task loss를 줄이는 방향으로 업데이트 되어서, previous task에 대한 성능이 떨어짐 (Weight drift)
- Weight drift와 비슷하게, weights이 바뀌는 것이 activations의 변화를 만들어내고, 이것이 네트워크 출력의 변화를 만들어냄 (Activation drift)
- 지금까지 학습한 task를 모두 처리할 수 있는 것이 목적이지만, previous task와 current task가 jointly trained되지 않기 때문에 네트워크 weights이 모든 task를 optimally 처리할 수 없음 (Inter-task confusion)
- 어떤 입력이 들어오던지 recent task classes로 예측하는 경향이 있음 (Task-recency bias)
이런 문제들을 해결하기 위해서 다음과 같은 연구들이 진행되고 있습니다.
- Regularization-based: new tasks를 학습하는 동안, previous tasks에 중요했던 요소들의 변화를 최소화 하는 방법
- Exemplar-based: previous tasks를 잊지 않기 위해서 previous tasks의 이미지 혹은 특징 벡터를 소량 저장하여 new tasks를 학습할 때 같이 제공하는 방법
- Bias-correction method: task-recency bias 문제를 중점적으로 해결하는 방법

Relation between class-IL methods. Taken from [Masana, Marc, et al., 2020]
Regularization approaches
Regularization approach는 new tasks를 학습하는 동안, previous tasks에 중요했던 정보를 최대한 변형하지 않도록 어떤 제약을 주는 전략을 말합니다. 대표적으로는 weight regularization 방법과, data regularization 방법으로 구분할 수 있습니다.
-
Weight regularization: 각 task에 대한 학습 후에 각 weight의 중요도를 평가하고, 다음 학습에서 이 weight들이 많이 변경되지 않도록 제약을 줌 -
EWC,PathInt,MAS,RWalk등 -
Data regularization: Knowledge distillation 기반으로 activation drift를 막는 방법. 현재 session의 입력에 대하여, 이전 session까지 들어온 class에 대한 출력이 학습 이전과 이후에 최대한 비슷해야 함. 출력 logits 뿐만 아니라 classifier 이전 layer의 representation을 distillation loss 계산에 사용하기도 함 -
LwF,LFL등 -
Recent developments in regularization -
LwM,DMC,GD등
Rehearsal approaches
Rehearsal approaches는 몇 개의 exemplar를 저장해두어서 이를 new task를 학습하는 동안 끼워넣거나(exemplar rehearsal), previous task의 이미지와 비슷한 이미지를 생성(pseudo-rehearsal)하여 forgetting을 막는 전략을 말합니다. 즉, previous task에서 저장된 데이터 혹은 생성된 데이터를 반복적으로 replay 하면서 forgetting을 막는 방법을 말합니다.
Exemplar는 previous task의 이미지 자체를 의미하거나 해당 이미지의 feature 벡터 값을 의미합니다. Class-incremental learning의 exemplar rehearsal이라는 개념은 iCaRL4에서 처음 제시되었습니다.
-
Memory type: continual 세팅에서는 이미 학습한 task의 데이터에 대해서는 접근할 수 없다는 가정이 있기 때문에 exemplar를 매우 소량만 사용할 수 있다고 가정합니다. 따라서 memory의 size에 대해 다음과 같은 옵션을 선택 가능합니다.
- Fixed memory: 메모리의 최대 용량이 고정. 따라서 새로운 데이터가 들어오기 위해 몇 개의 exemplar가 제거되어야 함
- Growing memory: 메모리의 용량이 증가하는 것을 허용. 하지만 오직 현재 task의 new sample의 추가만이 가능. 이 경우엔 메모리 cost가 선형적으로 증가
위의 두 경우 모두, 모든 class에 대한 equal representation을 보장하기 위해서 class 당 동일한 수의 exemplar가 저장되는 것이 강요됩니다.
-
Sampling strategies: previous task에서 exemplar를 몇 개만 고르는 방법으로써 다음과 같은 옵션을 선택 가능합니다.
- Random: 랜덤 샘플링. computational cost가 적게 든다는 장점
- Herding: 어떠한 규칙에 따라 조심스럽게 exemplar를 선정(주로 feature space 상에서의 특징을 분석하여 선정). iCaRL4에서는 exemplar mean과 real class mean이 최대한 가깝도록 exemplar를 선택함. Random 보다는 성능이 좋으나 computational cost 증가
실제 데이터를 exemplar로써 저장하는 것이 아니라 가상의 이미지를 생성해서 사용하는 방법은 pseudo-rehearsal이라고 합니다. 다만 대부분의 pseudo-rehearsal를 사용한 논문들이 MNIST와 같이 상대적으로 낮은 복잡도를 갖는 데이터 셋을 가지고 평가했기 때문에 더 복잡한 도메인으로 스케일 업이 가능하냐는 의문점을 가집니다.
Bias-correction approaches
Bias-correction approaches는 task-receny bias 문제를 해결하고자 하는 전략입니다. task-receny bias는 네트워크가 가장 최근에 배운 task에 biased되는 현상을 말하며, 이런 현상은 학습이 끝나는 시점에 심해집니다. 실제로 classifier를 분석해보아도 new class에 대해 큰 norm값을 가지며, 어떤 입력이 들어오던지 가장 최근 task 내 class로 예측하는 경향이 있습니다.
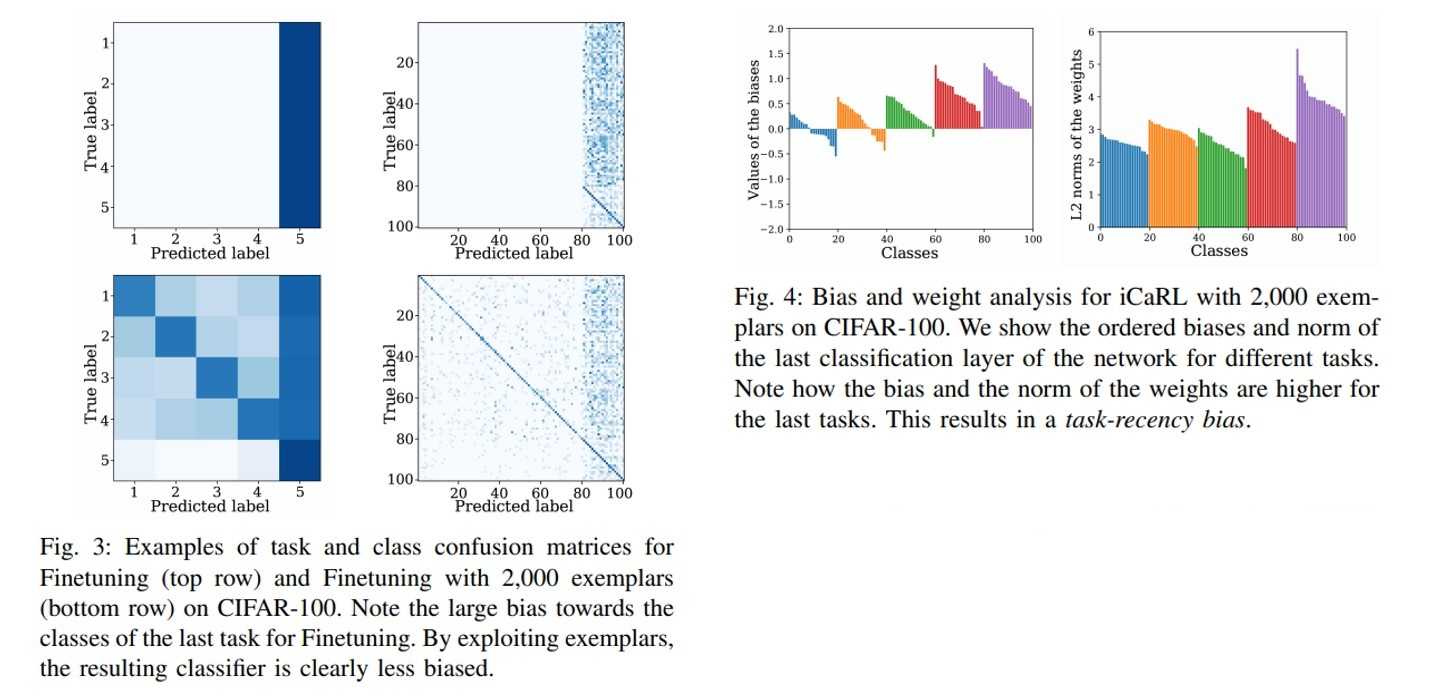
Task-receny bias problem. Taken from [Masana, Marc, et al., 2020]
이를 해결하기 위해서 new task에 대한 학습이 끝난 뒤에 previous task를 exemplar 기반으로 다시 학습하는 방법이나, output logit에 변형을 주는 방법이나, 출력에 특정 normalization을 걸어주는 방법 등이 제안되었습니다 - EEIL, BiC, LUCIR, IL2M 등
Others
새로운 task가 추가될 때 마다 network의 구조를 변경 및 추가하여 학습하는 방법도 존재합니다.
Progressive Neural Network5의 경우에는 새로운 task가 추가될 때 마다 병렬적으로 레이어를 추가하는 방법(lateral connection)을 통해, previous task를 학습한 weight은 변경하지 않으면서도 새로운 task를 학습할 수 있는 알고리즘을 제안하였습니다. 다만 이 방법은 previous task에 대한 weight을 freeze 하기 때문에 backward knowledge transfer가 일어나지는 않습니다.
Dynamically Expandable Network6의 경우에는 새로운 task가 추가될 때 마다 미리 정의된 규칙을 바탕으로 동적으로 네트워크의 구조를 변경합니다. PNN과는 달리 기존 layer의 weight을 변경하기도 하고(selevtive retraining), 새로운 task에 대한 loss가 너무 크다면 PNN 처럼 병렬적으로 layer를 추가하기도 하고(dynamic expansion), 기존 layer의 weight이 너무 많이 바뀌었다면 복제해서 새로운 hidden unit으로 만들어주기도 합니다(split and duplication).
Conclusion
- Exemplar-free 방법 중에서는 data regularization 방법이 weight regularization 방법보다 좋았다고 합니다.
- Exemplar-free method를 exemplar rehearsal method와 비교해 보았을 때 성능 상으로는 견주기는 힘들지만, 메모리 세팅에 있어서 자유도가 높기 때문에 별도로 나누어 비교를 하는 것이 좋다고 합니다.
- Exemplar로 finetuning 하는 것은 여러 복잡한 방법들보다 훨씬 간단하고 성능도 좋았다고 합니다.
- Weight regularization에 exemplars 방법을 결합한 것이 data regularization보다 좋은 경우들도 있었다고 합니다.
- Herding은 longer sequences of tasks에 대해서는 random 방식보다 좋았지만 short sequences of tasks에서는 그렇지 않았다고 합니다.
- 네트워크 구조는 class-IL 성능에 큰 영향을 미치며 특히 skip-connection의 유무가 큰 영향을 미쳤다고 합니다.
References
- Parisi, German I., et al. "Continual lifelong learning with neural networks: A review." Neural Networks 113 (2019): 54-71.↩
- Masana, Marc, et al. "Class-incremental learning: survey and performance evaluation." arXiv preprint arXiv:2010.15277 (2020).↩
- Liu, Bing. "Learning on the job: Online lifelong and continual learning." Proceedings of the AAAI Conference on Artificial Intelligence. Vol. 34. No. 09. 2020.↩
- Rebuffi, Sylvestre-Alvise, et al. "icarl: Incremental classifier and representation learning." Proceedings of the IEEE conference on Computer Vision and Pattern Recognition. 2017.↩
- Rusu, Andrei A., et al. "Progressive neural networks." arXiv preprint arXiv:1606.04671 (2016).↩
- Yoon, Jaehong, et al. "Lifelong learning with dynamically expandable networks." arXiv preprint arXiv:1708.01547 (2017).↩