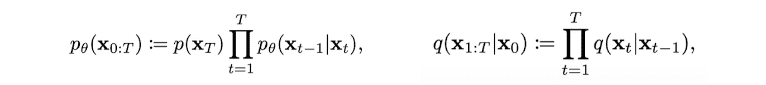2020년에 발표되었던 Denoising Diffusion Probabilistic Models 논문을 정리합니다.
DDPM은 2020년 전 까지는 GAN 중심으로 연구되었던 생성형 모델링 분야를 diffusion 기반으로 전환을 이끌어낸 아주 중요한 논문 중 하나입니다.
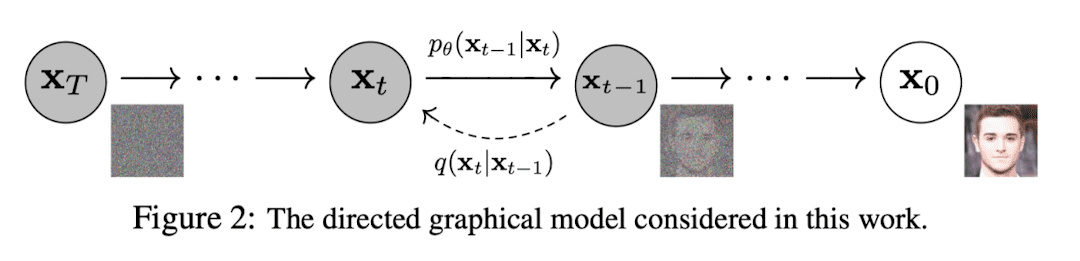
대부분의 generative model은 random noise를 샘플링 하고, 해당 random noise를 high quality sample로 만들어내는 방식으로 동작하는데, diffusion model도 마찬가지입니다. 위 이미지에서 처럼 x0로 표현된 데이터에 noise를 순차적으로 주입하여 N(0,I)으로 만든 뒤, 그 역 과정을 모델이 학습하는 방식으로 동작합니다. 그러면 모델은 결국 N(0,I)에서 샘플링 된 random noise로 부터 high quality sample을 만들어낼 수 있게 됩니다.
Background
Diffusion model에는 forward process(diffusion process) q와 backward process pθ라는 개념이 존재하며, 각각 아래의 식으로 표현됩니다.
x1:T: x0에서 xT로 가면서 각 단계에서 점진적으로 노이즈가 추가되는 중간 상태
pθ(xT)=N(xT;0,I) 형태로 정의하며 pθ(x0:T)는 Markov chain로 정의
x1,⋯,xT는 latent variable이고 x0와 같은 차원인 pixel space에 존재
여기서, 모델을 의미하는 pθ의 목표는 xt가 주어졌을 때, xt−1가 어떤 μ와 Σ를 가질지 예측하는 것입니다. 따라서 conditional probability pθ를 일단 아래와 같이 표현할 수 있습니다.
pθ(xt−1∣xt):=N(xt−1;μθ(xt,t),Σθ(xt,t))
그리고 모델 학습 단계로 넘어가보면, 모든 생성모델은 pθ(x0)의 likelihood를 높이는 것이 목표이므로, −logpθ(x0)를 최소화하도록 loss 식을 설정할 수 있고, 수식으로 작성시 아래와 같이 표현됩니다. 식의 자세한 유도 과정은 논문의 Appendix A에서 확인하실 수 있습니다.
위의 loss 식에서 diffusion model에 해당하는 Lt−1을 더 살펴볼 필요가 있습니다. 여기서 pθ(xt−1∣xt)가 닮아야하는 q(xt−1∣xt,x0)는 아래와 같이 표현됩니다. 이 때 βt는 forward process에서 t 시점 데이터의 variance를 의미합니다.
q(xt−1∣xt,x0) where μ~t(xt,x0)=N(xt−1;μ~t(xt,x0),β~tI),:=1−αˉtαˉt−1βtx0+1−αˉtαt(1−αˉt−1)xt and β~t:=1−αˉt1−αˉt−1βt
q(xt∣xt−1)를 기반으로 q(xt−1∣xt,x0) 형태로 다시 표현하면 이런 형태가 되는구나.. 까지 받아들이면 Background 파트가 끝이 납니다.
Diffusion Models and Denoising Autoencoders
DDPM 저자들은 diffusion model의 기본적인 loss 식을 하나씩 살펴보며 다시 정리합니다.
먼저 LT term을 확인해보겠습니다. 식에서 p(xT)는 N(xT;0,I)로 고정이고, q(xt∣x0)는 βt에 따라 달라집니다. 본 논문에는 βt를 상수로 설정하였고, 따라서 LT는 parameter 최적화와 아무 관련이 없게되어 무시할 수 있게 됩니다.
그 다음으로는 Lt−1 term을 확인해보겠습니다. q(xt−1∣xt,x0)와 pθ(xt−1∣xt) 분포를 위 Background 파트에서 살펴본 내용 대로 다시 적어보면 아래와 같습니다.
q(xt−1∣xt,x0) where μ~t(xt,x0)=N(xt−1;μ~t(xt,x0),β~tI),:=1−αˉtαˉt−1βtx0+1−αˉtαt(1−αˉt−1)xt and β~t:=1−αˉt1−αˉt−1βt
pθ(xt−1∣xt):=N(xt−1;μθ(xt,t),Σθ(xt,t))
여기서 우리가 학습해야하는 파라미터는 결국 t 시점의 q(xt−1∣xt,x0)의 평균과 공분산을 예측하는 μθ와 Σθ입니다. 그런데 논문에서는 Σθ를 σt2I 형태의 time dependent constant로 설정합니다. 즉, Lt−1가 학습할 파라미터는 μθ 밖에 없다는 것을 의미합니다. 따라서 이를 L2 loss 형태로 정리하면 아래와 같이 표현됩니다.
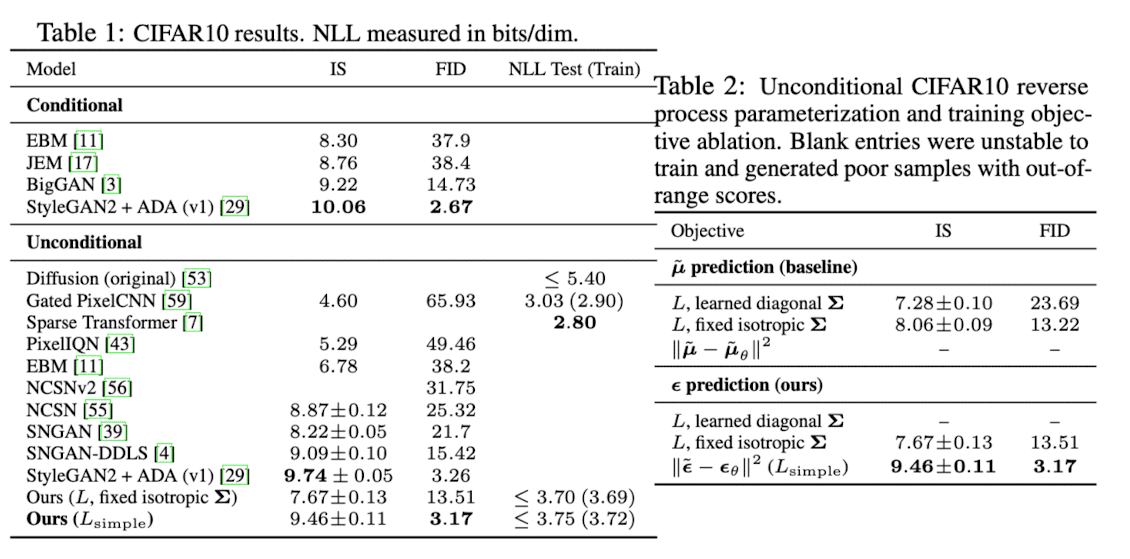
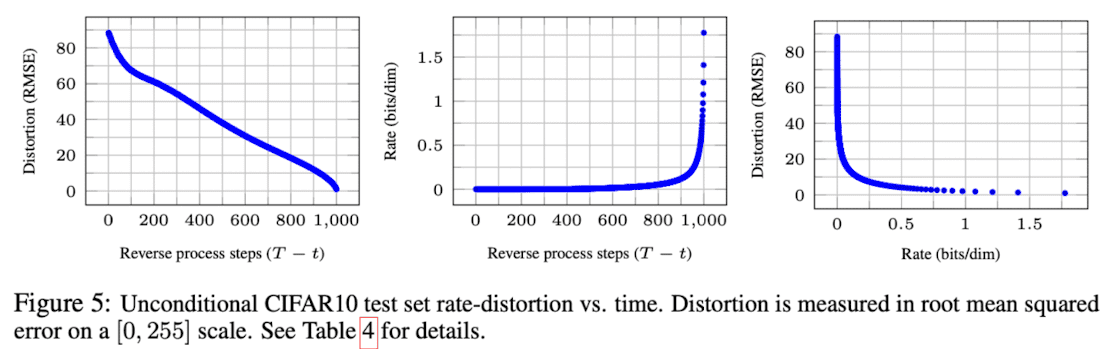
실험을 위해 T=1000으로 설정하였고, βt는 β1=10−4에서 βT=0.02로 선형적으로 증가하도록 설정하였습니다. Reveser process에서의 backbone은 U-Net을 사용하였고 매 timestep 마다의 U-Net은 동일한 모델을 parameter share하여 사용합니다.
두 원본 이미지에 forward process를 수행 후에, linear interpolation된 noise를 다시 복원해내는 것도 가능합니다.
Reference
Ho, Jonathan, Ajay Jain, and Pieter Abbeel. "Denoising diffusion probabilistic models." Advances in neural information processing systems 33 (2020): 6840-6851.